
[ad_1]
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of the last week’s stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week, Google dominated the AI news cycle with a range of new products that launched at its annual I/O developer conference. They run the gamut from a code-generating AI meant to compete with GitHub’s Copilot to an AI music generator that turns text prompts into short songs.
A fair number of these tools look to be legitimate labor savers — more than marketing fluff, that’s to say. I’m particularly intrigued by Project Tailwind, a note-taking app that leverages AI to organize, summarize and analyze files from a personal Google Docs folder. But they also expose the limitations and shortcomings of even the best AI technologies today.
Take PaLM 2, for example, Google’s newest large language model (LLM). PaLM 2 will power Google’s updated Bard chat tool, the company’s competitor to OpenAI’s ChatGPT, and function as the foundation model for most of Google’s new AI features. But while PaLM 2 can write code, emails and more, like comparable LLMs, it also responds to questions in toxic and biased ways.
Google’s music generator, too, is fairly limited in what it can accomplish. As I wrote in my hands on, most of the songs I’ve created with MusicLM sound passable at best — and at worst like a four-year-old let loose on a DAW.
There’s been much written about how AI will replace jobs — potentially the equivalent of 300 million full-time jobs, according to a report by Goldman Sachs. In a survey by Harris, 40% of workers familiar with OpenAI’s AI-powered chatbot tool, ChatGPT, are concerned that it’ll replace their jobs entirely.
Google’s AI isn’t the end-all be-all. Indeed, the company’s arguably behind in the AI race. But it’s an undeniable fact that Google employs some of the top AI researchers in the world. And if this is the best they can manage, it’s a testament to the fact that AI is far from a solved problem.
Here are the other AI headlines of note from the past few days:
- Meta brings generative AI to ads: Meta this week announced an AI sandbox, of sorts, for advertisers to help them create alternative copies, background generation through text prompts and image cropping for Facebook or Instagram ads. The company said that the features are available to select advertisers at the moment and will expand access to more advertisers in July.
- Added context: Anthropic has expanded the context window for Claude — its flagship text-generating AI model, still in preview — from 9,000 tokens to 100,000 tokens. Context window refers to the text the model considers before generating additional text, while tokens represent raw text (e.g., the word “fantastic” would be split into the tokens “fan,” “tas” and “tic”). Historically and even today, poor memory has been an impediment to the usefulness of text-generating AI. But larger context windows could change that.
- Anthropic touts ‘constitutional AI’: Larger context windows aren’t the Anthropic models’ only differentiator. The company this week detailed “constitutional AI,” its in-house AI training technique that aims to imbue AI systems with “values” defined by a “constitution.” In contrast to other approaches, Anthropic argues that constitutional AI makes the behavior of systems both easier to understand and simpler to adjust as needed.
- An LLM built for research: The nonprofit Allen Institute for AI Research (AI2) announced that it plans to train a research-focused LLM called Open Language Model, adding to the large and growing open source library. AI2 sees Open Language Model, or OLMo for short, as a platform and not just a model — one that’ll allow the research community to take each component AI2 creates and either use it themselves or seek to improve it.
- New fund for AI: In other AI2 news, AI2 Incubator, the nonprofit’s AI startup fund, is revving up again at three times its previous size — $30 million versus $10 million. Twenty-one companies have passed through the incubator since 2017, attracting some $160 million in further investment and at least one major acquisition: XNOR, an AI acceleration and efficiency outfit that was subsequently snapped up by Apple for around $200 million.
- EU intros rules for generative AI: In a series of votes in the European Parliament, MEPs this week backed a raft of amendments to the bloc’s draft AI legislation — including settling on requirements for the so-called foundational models that underpin generative AI technologies like OpenAI’s ChatGPT. The amendments put the onus on providers of foundational models to apply safety checks, data governance measures and risk mitigations prior to putting their models on the market
- A universal translator: Google is testing a powerful new translation service that redubs video in a new language while also synchronizing the speaker’s lips with words they never spoke. It could be very useful for a lot of reasons, but the company was upfront about the possibility of abuse and the steps taken to prevent it.
- Automated explanations: It’s often said that LLMs along the lines of OpenAI’s ChatGPT are a black box, and certainly, there’s some truth to that. In an effort to peel back their layers, OpenAI is developing a tool to automatically identify which parts of an LLM are responsible for which of its behaviors. The engineers behind it stress that it’s in the early stages, but the code to run it is available in open source on GitHub as of this week.
- IBM launches new AI services: At its annual Think conference, IBM announced IBM Watsonx, a new platform that delivers tools to build AI models and provide access to pretrained models for generating computer code, text and more. The company says the launch was motivated by the challenges many businesses still experience in deploying AI within the workplace.
Other machine learnings
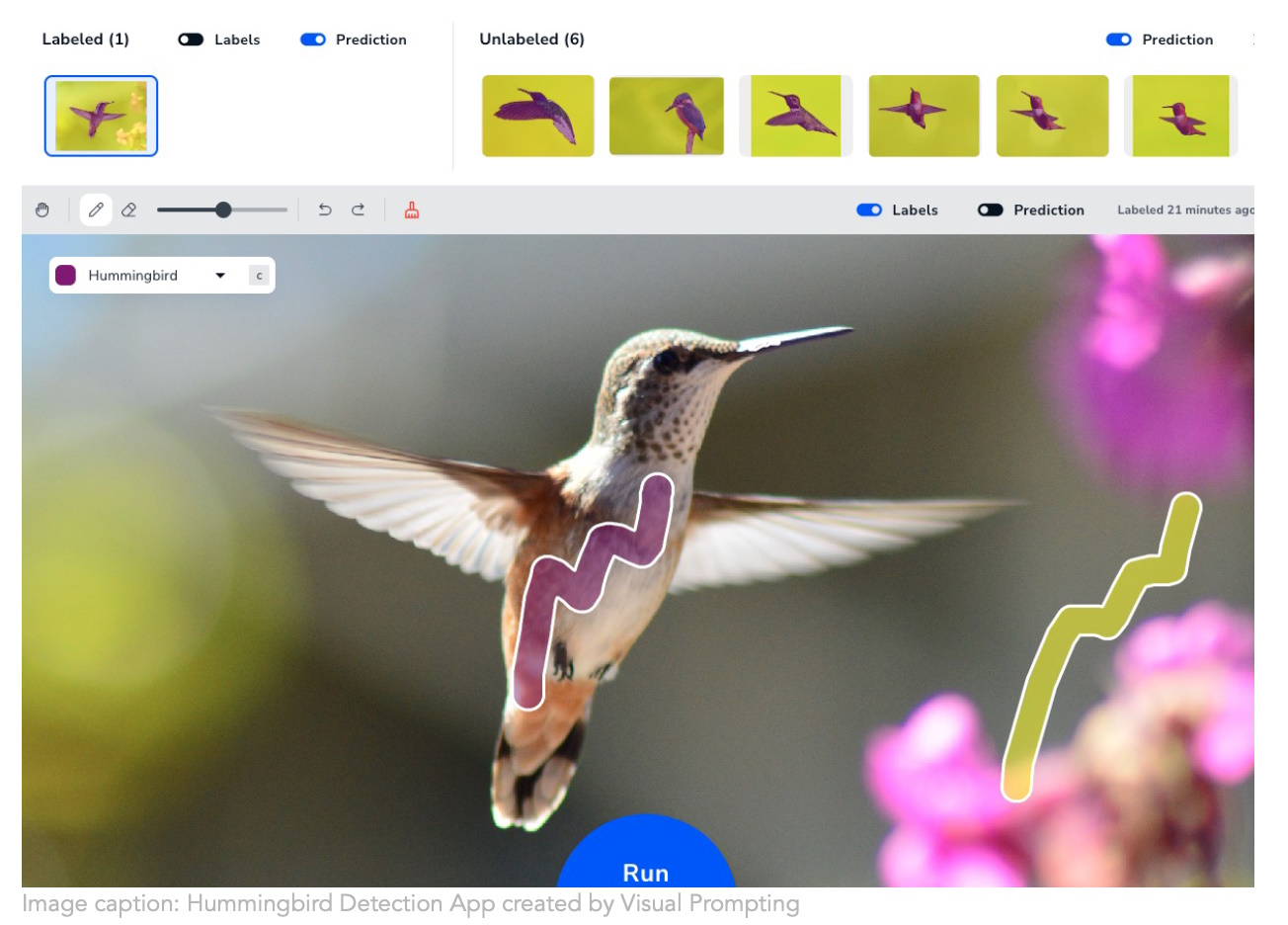
Image Credits: Landing AI
Andrew Ng’s new company Landing AI is taking a more intuitive approach to creating computer vision training. Making a model understand what you want to identify in images is pretty painstaking, but their “visual prompting” technique lets you just make a few brush strokes and it figures out your intent from there. Anyone who has to build segmentation models is saying “my god, finally!” Probably a lot of grad students who currently spend hours masking organelles and household objects.
Microsoft has applied diffusion models in a unique and interesting way, essentially using them to generate an action vector instead of an image, having trained it on lots of observed human actions. It’s still very early and diffusion isn’t the obvious solution for this, but as they’re stable and versatile, it’s interesting to see how they can be applied beyond purely visual tasks. Their paper is being presented at ICLR later this year.
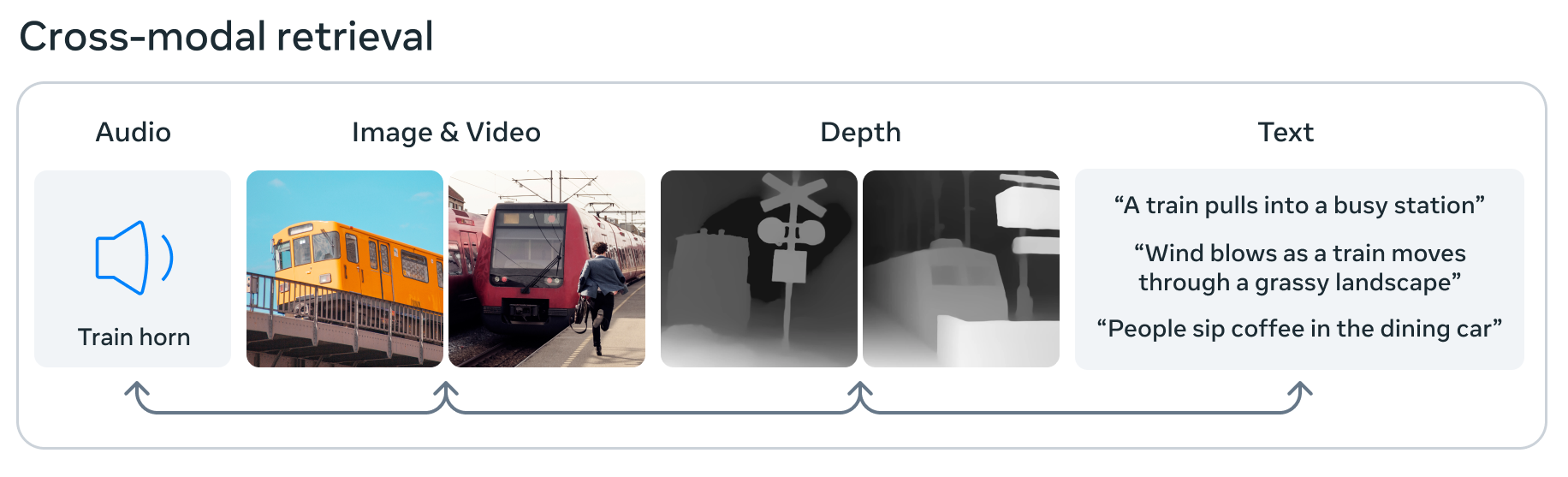
Image Credits: Meta
Meta is also pushing the edges of AI with ImageBind, which it claims is the first model that can process and integrate data from six different modalities: images and video, audio, 3D depth data, thermal info, and motion or positional data. This means that in its little machine learning embedding space, an image might be associated with a sound, a 3D shape, and various text descriptions, any one of which could be asked about or used to make a decision. It’s a step towards “general” AI in that it absorbs and associates data more like the brain — but it’s still basic and experimental, so don’t get too excited just yet.
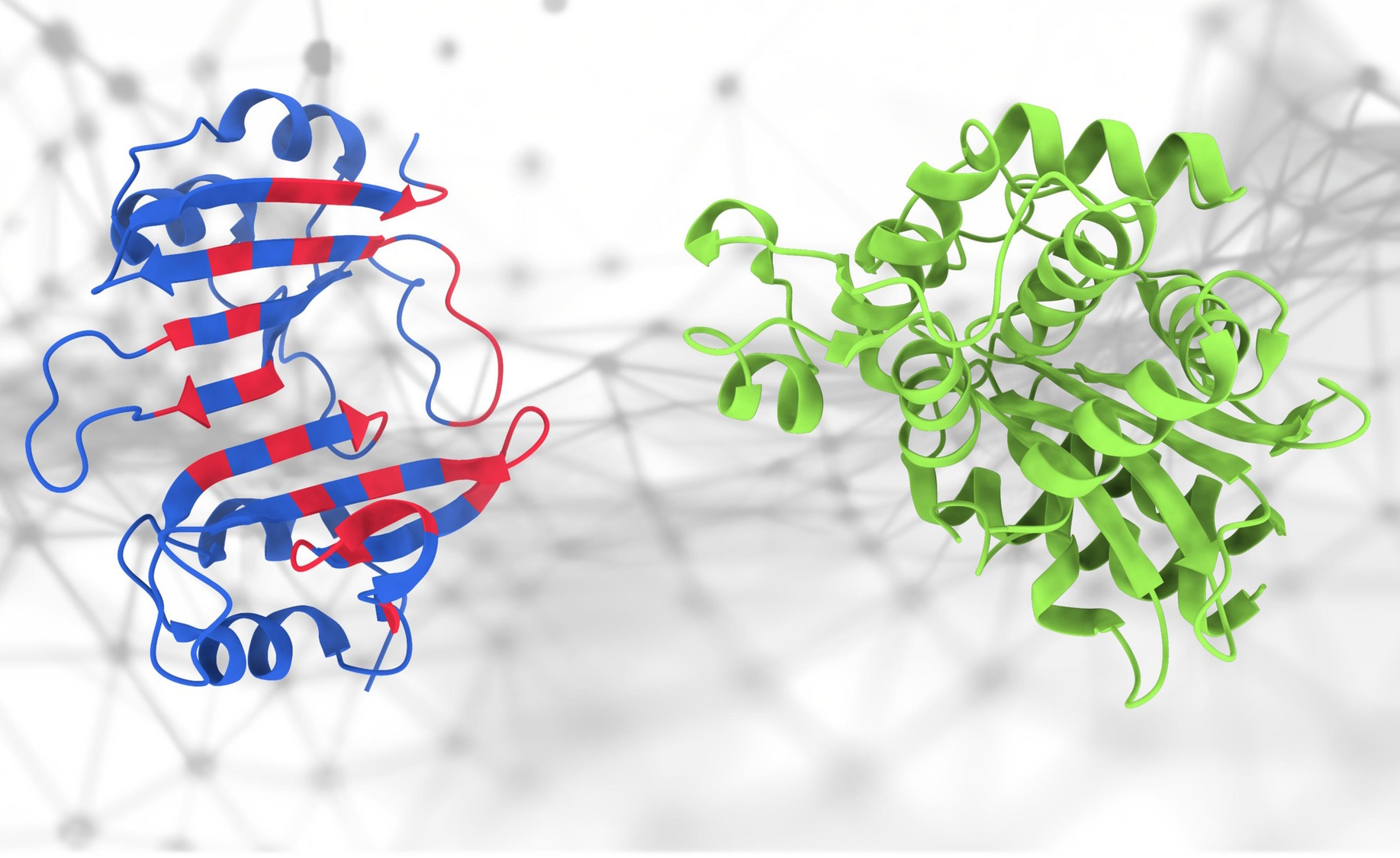
If these proteins touch… what happens?
Everyone got excited about AlphaFold, and for good reason, but really structure is just one small part of the very complex science of proteomics. It’s how those proteins interact that is both important and difficult to predict — but this new PeSTo model from EPFL attempts to do just that. “It focuses on significant atoms and interactions within the protein structure,” said lead developer Lucien Krapp. “It means that this method effectively captures the complex interactions within protein structures to enable an accurate prediction of protein binding interfaces.” Even if it isn’t exact or 100% reliable, not having to start from scratch is super useful for researchers.
The feds are going big on AI. The President even dropped in on a meeting with a bunch of top AI CEOs to say how important getting this right is. Maybe a bunch of corporations aren’t necessarily the right ones to ask, but they’ll at least have some ideas worth considering. But they already have lobbyists, right?
I’m more excited about the new AI research centers popping up with federal funding. Basic research is hugely needed to counterbalance the product-focused work being done by the likes of OpenAI and Google — so when you have AI centers with mandates to investigate things like social science (at CMU), or climate change and agriculture (at U of Minnesota), it feels like green fields (both figuratively and literally). Though I also want to give a little shout out to this Meta research on forestry measurement.

Doing AI together on a big screen — it’s science!
Lots of interesting conversations out there about AI. I thought this interview with UCLA (my alma mater, go Bruins) academics Jacob Foster and Danny Snelson was an interesting one. Here’s a great thought on LLMs to pretend you came up with this weekend when people are talking about AI:
These systems reveal just how formally consistent most writing is. The more generic the formats that these predictive models simulate, the more successful they are. These developments push us to recognize the normative functions of our forms and potentially transform them. After the introduction of photography, which is very good at capturing a representational space, the painterly milieu developed Impressionism, a style that rejected accurate representation altogether to linger with the materiality of paint itself.
Definitely using that!
[ad_2]
Source link





